
概要
「五十音順の名簿であ行の名字多すぎない?」という疑問は一般的なもののようであり、実際 Twitter で「あ行 名字 多い」で調べると同様の感想が大量にヒットする。
Mar 27, 2020
この大学では人数を均等にするためにあ行を「あ・い」「う・え・お」に分割しているようである。確かに私も「い」から始まる姓の持主ではあるのだが、出席番号順では 40 人クラスで 8 番目なこともあったし、これは明らかに苗字の五十音表における分布の偏りを示唆しているように思える。
この問題については先人があらかた調べをつけているようであり、例えば以下の記事などがある。
上記記事によるとあ行は 18.1% で最多なようであるが、せっかくなので分布を可視化してみようと思う。今回は個人的に好きな「カルトグラム (cartogram)」という手法を用いることする。
Sep 3, 2021
エリアカルトグラムとは、既存の地図を歪め、その地域の人口などを土地面積で置き換えたものである。今回は、名字の最初の文字別人口を計算し、それに基づいて五十音表を歪めてみようと思う。
手法
データ収集
上記を実現するためには、まず日本の名字別人口のデータが必要になる。先述の記事で用いられたデータソースはすでにリンク切れしていたため、今回は 名字由来 net の名字ランキング (40000 位まで) を使用することにした。本ランキングは漢字表記の名字毎に集計されているので、例えば「東」に「ひがし」と「あずま」がひとくくりになってしまっているが、そこはまあしゃーなしとしてもっとも代表的と思われる読み 1 つを採用する方針とした。以上のようにして、日本の名字およびその読み、人口をまとめた csv を作成した。
以上を、代表的な読みの最初の文字別に分類したものがこちらである。濁点を含むものについてはそれを取り除いたひらがなで集計を行った。一部を以下に示す。
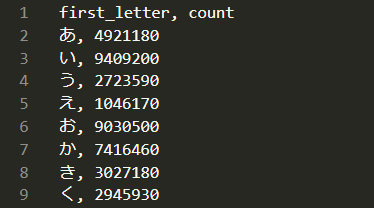
冒頭の話であ行の新入生が「あ・い」と「う~お」に分けられているという話があったが、「あ・い」で 1433 万人、た行全体で 1400 万人なのでまあ妥当なのではと思えてくる。
五十音表を地球上に設置する
上記の csv で数字だけ見ていてもイマイチピンとこないので、先述の通りカルトグラムを描いてみることにする。調べてみたところ R にあるライブラリ cartogram を利用できそうな感じであったが、そもそもは地図に対して適用するものであるため、まずは五十音表を地図データ (geojson など) の形式で作成する必要がある。五十音のマス目を地球上のどこに設置してもいいのだけど、今回は適当に緯度経度を設定して京都に置いてみることにした。
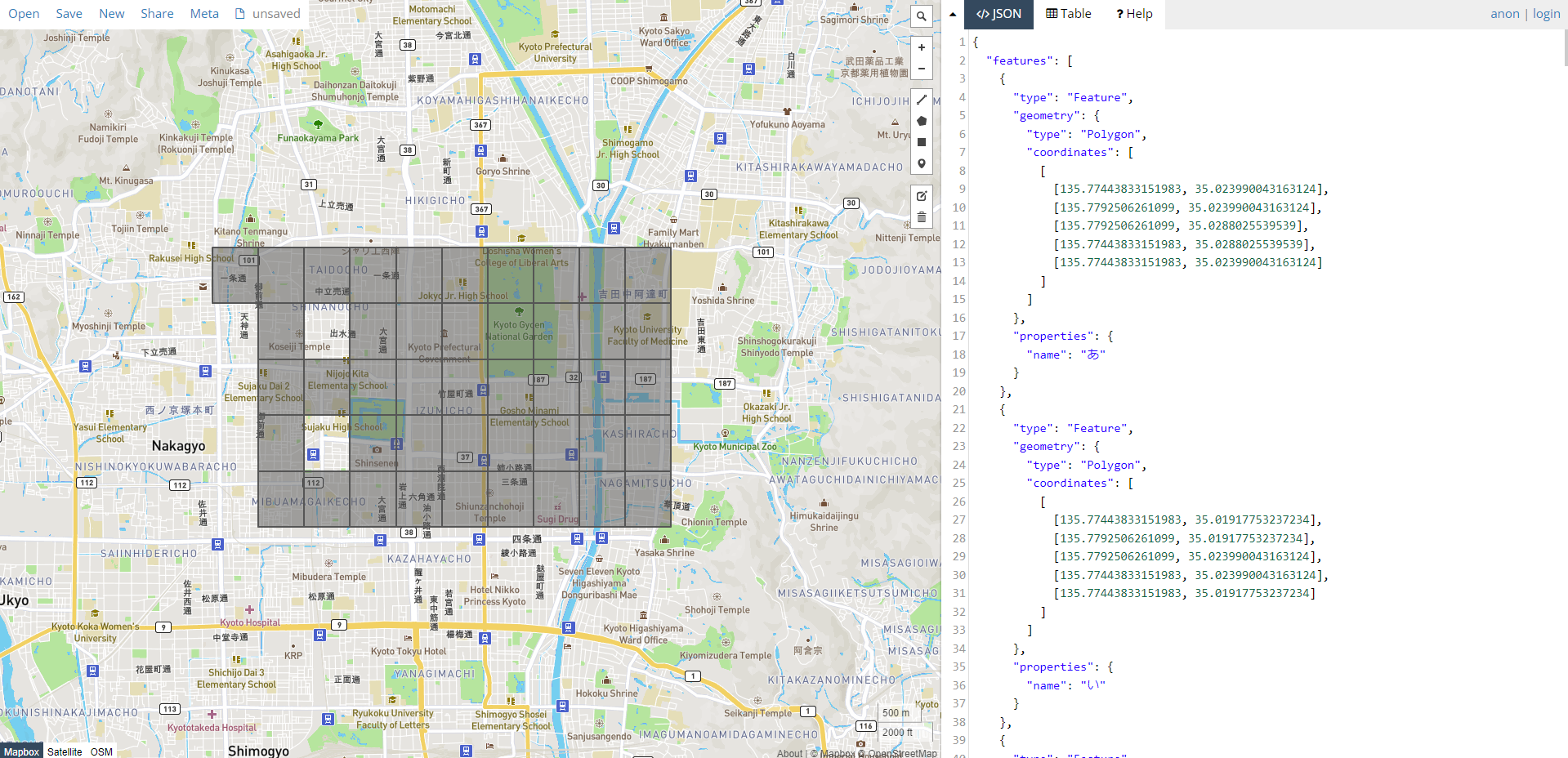
上図は Python で上手いこと geojson ファイルを作成し、geojson.io で実際の地図上に重ねてみたもの。「を」「ん」から始まる名字は一つもなかったので今回は割愛させていただいた。
カルトグラムを描いてみる
まずは作成した地図データを表示してみるところから。上記のデータは緯度経度で座標を指定しており、これを投影変換する必要がある。今回は、京都府を含む平面直角座標 (EPSG 6674) で transform してみることにする。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
library(cartogram)
library(tidyverse)
library(geojsonio)
library(ggplot2)
library(sf)
spdf <- geojson_read("aiueo_table.json", what = "sp")
stat <- read.table("stat.csv", sep = ",", header = TRUE)
spdf@data <- spdf@data %>% left_join(., stat, by = c("name" = "first_letter"))
sfno <- st_as_sf(spdf)
sfproj <- st_transform(sfno, crs = 6674)
windowsFonts(MEI = windowsFont("IPAexGothic"))
ggplot() +
geom_sf(data = sfproj) +
geom_sf_label(data = sfproj, aes(label = name), size = 8, family = "MEI", label.size = 0, fontface = "bold", alpha = 0.5, label.r = unit(0.4, "lines"), label.padding = unit(0.4, "lines")) +
theme(text = element_text(size = 24), axis.ticks = element_blank(), axis.title = element_blank(), axis.text = element_blank())
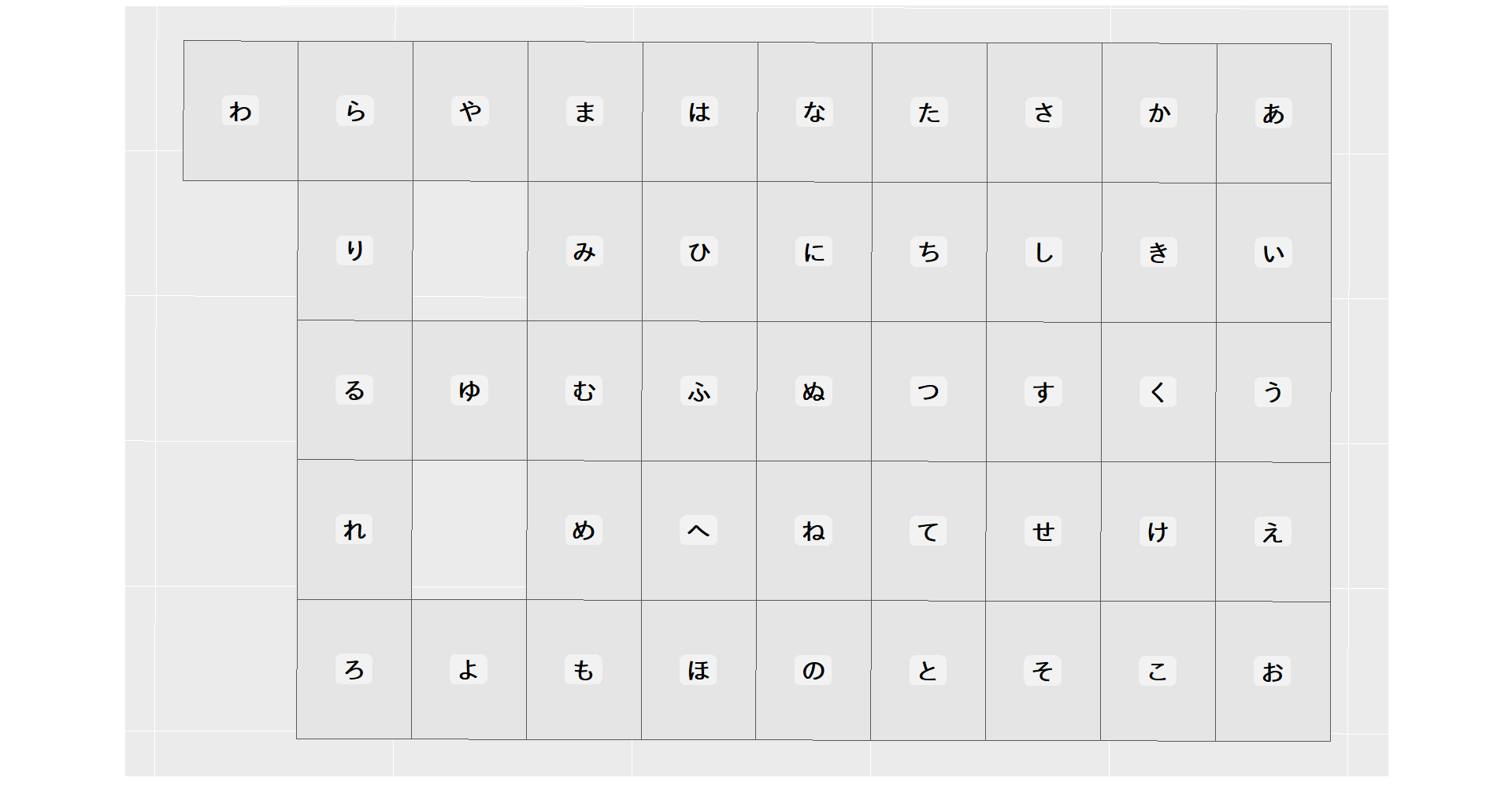
こんな感じで五十音表を ggplot で描いてみた。今度はこれを歪めてみよう。
1
2
3
4
5
6
cartogram <- cartogram_cont(sfproj, "count", itermax = 50)
ggplot() +
geom_sf(data = cartogram, aes(fill = count)) +
geom_sf_label(data = cartogram, aes(label = name), size = 8, family = "MEI", label.size = 0, fontface = "bold", alpha = 0.5, label.r = unit(0.4, "lines"), label.padding = unit(0.4, "lines")) +
theme(text = element_text(size = 24), axis.ticks = element_blank(), axis.title = element_blank(), axis.text = element_blank())
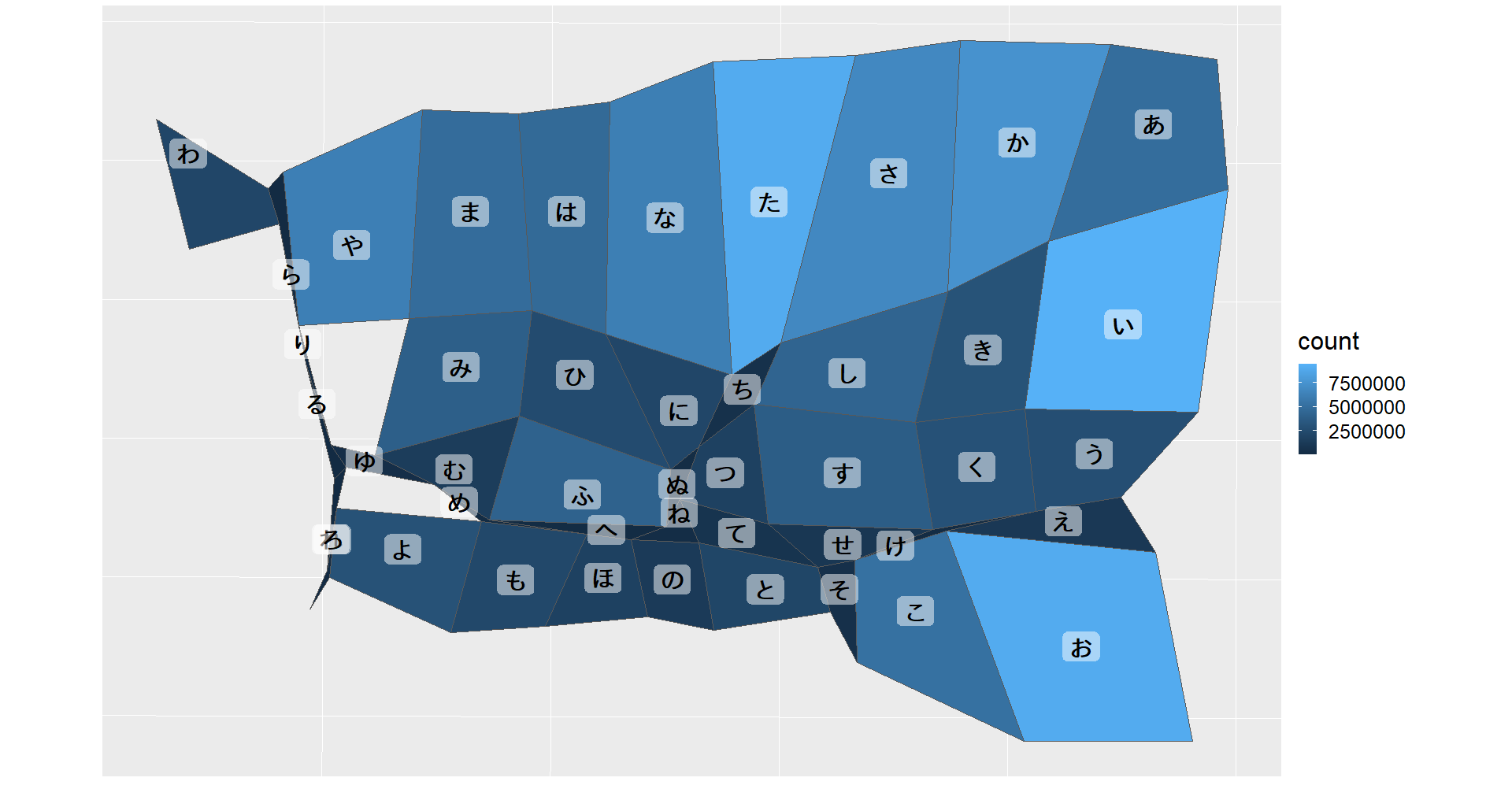 名字由来 net のデータをもとに作成
名字由来 net のデータをもとに作成
感想
- 眺めてみてまず思うのが、「ら」行あまりにも細すぎないかということである。実際に数字を確認してみると、最も人数が少なかった「れ」から始まる名字の人はこの統計上 2100 人 (全体の 0.001%) しかいないらしい。
- 横に眺めてみると、「あ」段は全体に数が多いことがわかる。逆に「え」段はどの行においても圧倒的に少ない (そもそも名字に限らず日本語の単語全体に同様の傾向があったりするんだろうか? 日本語のエンドユーザであって成り立ちは知らないので、詳しい方は教えてください)。
さいごに
今回のデータ (名字の最初の文字別人口、五十音表の geojson データ) は こちらのレポジトリ で参照できる。五十音表を歪めてみたくなった方はご利用ください。